
前編では「なぜNextPlayを作ったか」と、バイブコーディングの概要を書きました。
中編では実際の開発の中身を書きます。最初の1週間で動くものを作り、2週目にコア機能を実装する中でぶつかった壁の話です。


まず「動作するアプリを作る」

開発初日、最優先にしたのはこれでした。
「ログイン後にダッシュボードが落ちずに表示される」
完成度はひとまず置いておいて、まずアプリとして「最低限の動作をすること」ことを確認したかった。
方針を伝えて、AIコーディングエージェント(OpenAI Codex)に最初のMVPを出してもらいました。ところが、出てきたのは自分が思い描いていたものと全然違うアプリでした。
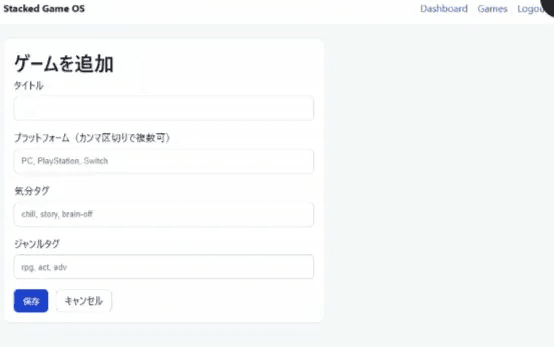
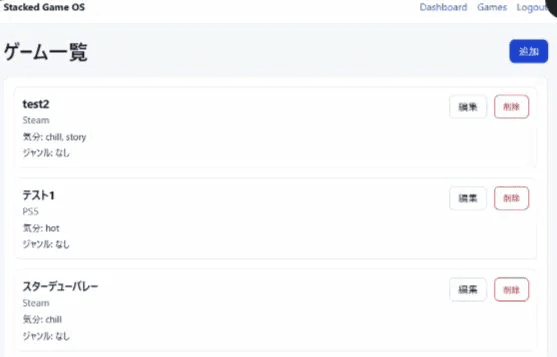
Codexが作ったのは「ユーザーが自分でゲームのタイトルやジャンルを入力して、マイリストを作る」システム。いわばゲーム管理ツールです。
でも自分が作りたかったのは「ゲームデータベースから自動で候補を引いてきて、今の気分に合う1本を提案してくれる」アプリです。方向が真逆。
まずは認証画面・ホーム画面・マイリストが動作することだけ確認して、すぐに修正指示を出しました。
ここで実感したのは、前編でも書いた通りAIはこちらの意図を読み取ってはくれないということです。
「ゲームのおすすめアプリを作って」ではダメで、「どこからデータを取ってきて、どう提案するか」まで伝えないと、AIは自分なりに解釈して別のものを作ってしまう。
- ゲームを登録する機能を作って
- ユーザが選択したフィルタ項目やマイリストに基づいて、ゲームデータベースから自動でおすすめタイトルを提案
- ユーザは、おすすめタイトルに対して「気になる」「プレイ済み」「ブロック」のステータスを付与でき、マイリストに保存される
「誰が・何をしたとき・何が起きるか」まで書く。 この差が、返ってくるコードの品質に直結しました。
認証の壁をSupabaseで突破する

「ログイン機能」はWebアプリで必須ですが、ゼロから作ろうとすると複雑です。パスワードの保存方法、セッション管理、セキュリティ対策……
今回はSupabaseというサービスに認証を丸ごと任せました。Supabaseはデータベース・認証・ストレージをまとめて提供するサービスで、以前のバイブコーディングで使った経験がありました。自分から提案するつもりだったんですが、Codexから先に提案されて、そのまま採用。デプロイ先のVercelについても同様でした。
自分のアプリにログインできた瞬間は、地味に毎回感動します。
普段使っているサービスと同じように認証が動いている。Supabaseの管理画面を開くと、サインアップしたアカウントがちゃんとテーブルに追加されている。内部の仕組みは詳しくわからないけど(笑)
ただ、同時に不安も芽生えました。
結局、セキュリティの定番書である通称「徳丸本」を買いました。そしてCodexにも「認証まわりで確認すべきセキュリティ項目を洗い出して、最適化して」と依頼して調整しました。
バイブコーディングは「AIがコードを書いてくれる」けど、自分が理解していない部分への不安は消えない。 その不安をどう処理するかは、自分の仕事でした。
1週間でできたもの
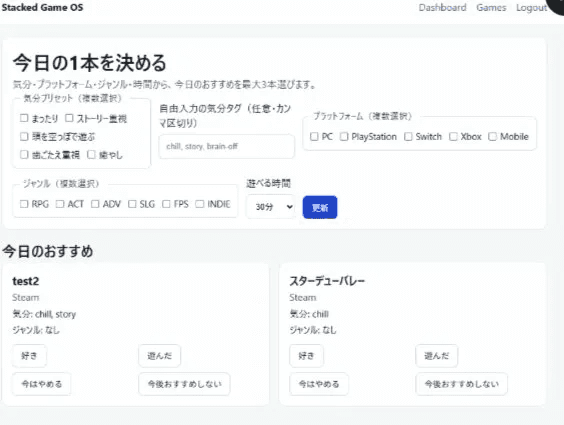
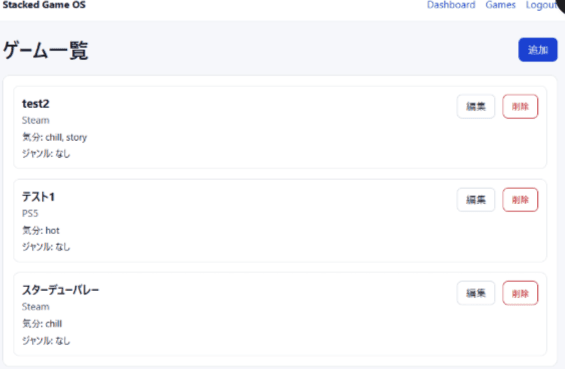
- メール認証(ログイン・サインアップ)
- ホーム画面(おすすめ提案画面)
- マイリストもどき(ステータス登録ゲームの一覧表示)
アプリの名前はまだ「Stacked Game OS」でした。AIがつけたコードネームをそのまま使っていた時期です(「NextPlay」に変わるのはもう少し先の話)。
でも、スクリーンショットを見返すと気づくことがあります。「今日の1本を決める」というコア体験の形は、この時点ですでに見えていました。
コア機能を作る中でぶつかった壁
軸は最初から決まっていました。「プラットフォームを横断して、今の気分に合う1本を提案するアプリ」。Steamを開いて30分無駄にするあの体験をなくしたいという課題感はブレなかった。
- RAWG API連携:ゲームデータベースからゲーム情報を取得する
- OpenAI API連携:候補のリランキング(並び替え)で推薦精度を上げる
- フィルタ機能:時代・プラットフォーム・ジャンルで候補を絞る
- 4択アクション:「気になる」「遊んだ」「ブロック」「次へ」でユーザーの好みを学習する
2週目はその軸に向かって、コア機能を一気に実装していく期間でした。
ここで3つの壁にぶつかりました。
壁①:API初体験の手探り
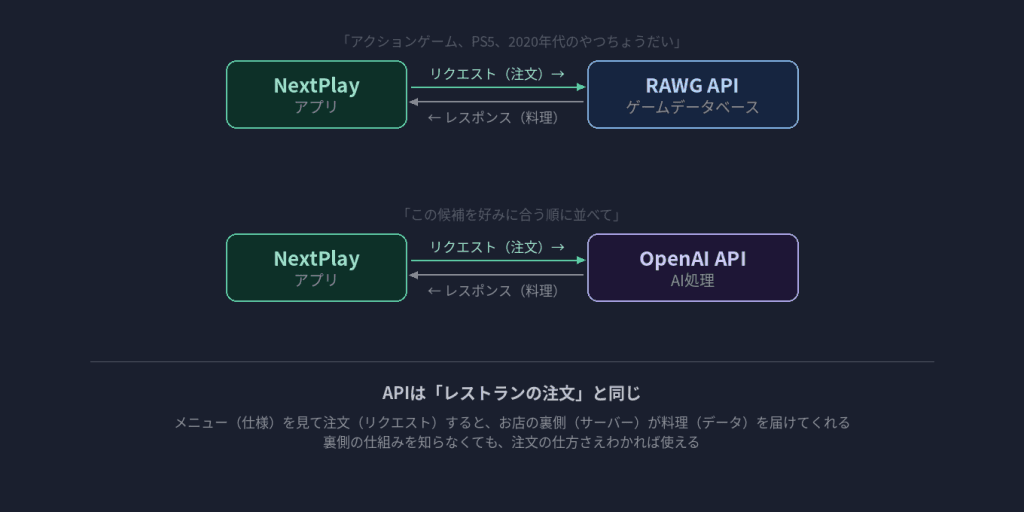
API連携は初めての経験でした。
ゲームのデータベースにどんなサービスがあるかすら知らなかったので、まずはリサーチから依頼しました(これはCodexではなくChatGPTに聞いた記憶があります。調査系はチャットAIの方がやりやすかった)。そこでRAWG APIという、ゲーム情報を網羅的に提供するデータベースに辿り着きました。
APIの存在やなんとなくの役割は知っていましたが、今回実際に連携にいたることでより現実の技術として腹落ちすることができました。
壁②:フィルタとデータが噛み合わない
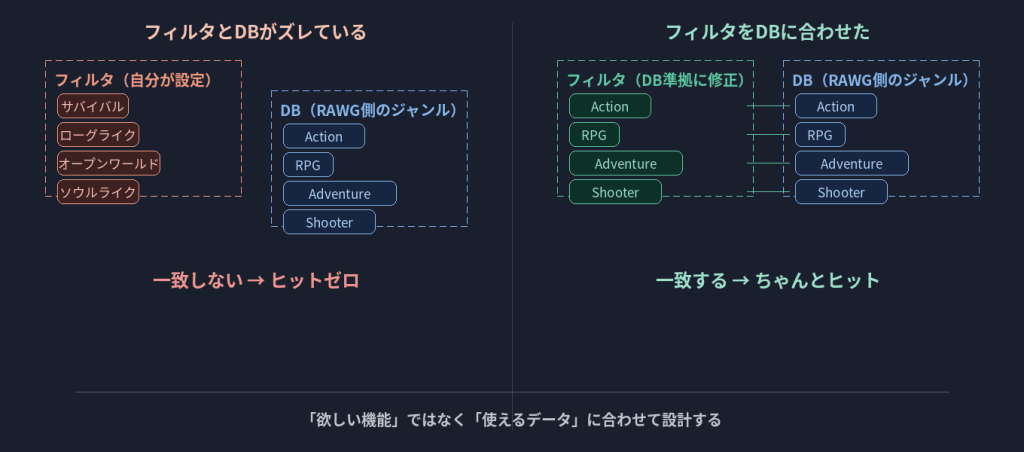
フィルタ機能を作ったとき、はじめは無邪気に自分の好きなジャンルを追加していきました。「サバイバル」「ローグライク」とか最近人気だしいいやろと。
原因はシンプルで、RAWG APIのデータベースに存在しないジャンル名をフィルタに設定していたのです。自分の頭の中にあるジャンル分類と、データベースが持っているジャンル分類は違う。
Codexに「フィルタの項目がデータベースの実データと一致しているか確認して」と依頼して、DBの分類に合わせてフィルタを再設計しました。
「欲しい機能」ではなく「使えるデータ」に合わせて設計する。
取れないデータを前提にした画面は、いつも空っぽかエラーかのどちらかになります。
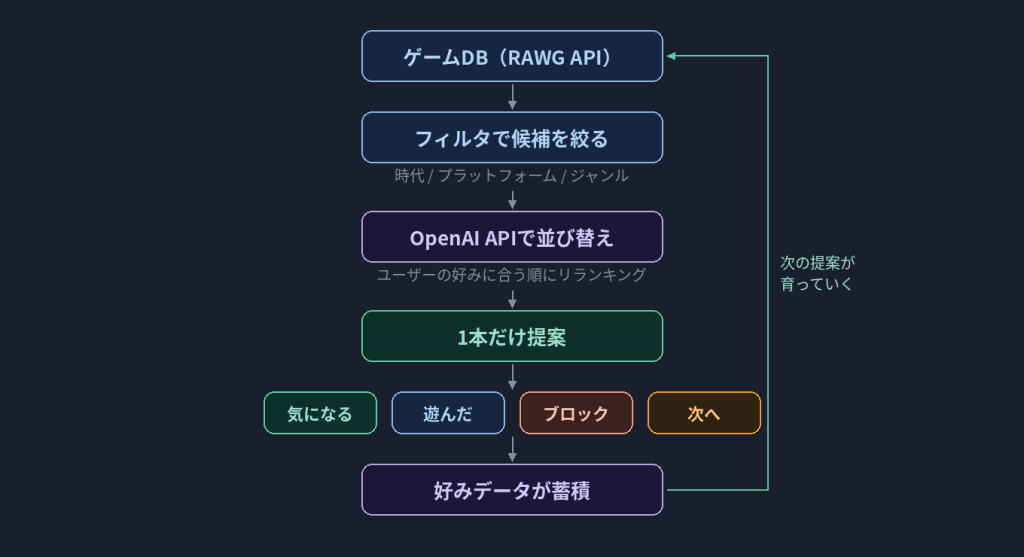
壁③:レコメンドロジックの試行錯誤
最初は、ゲームの候補をそのままAIに渡してリランキング(好みに合う順に並び替え)させていました。
膨大な量のデータをAIに渡すと処理時間がかかりすぎるし、途中でエラーになる可能性も高い。
そこで二段構成にしました。まずフィルタ(時代・プラットフォーム・ジャンル)で候補を絞り、その絞った候補のから「メタスコア」の高い順に上位約10本だけをOpenAI APIに渡して並び替える。
![【図解】二段構成のレコメンド処理 [全ゲームDB] →→ [フィルタで候補を絞る] →→ [候補リスト(数十件)] →→ [OpenAI APIで並び替え] →→ [1本を提案] ※「全部をAIに渡すと遅い&エラー」→「フィルタで減らしてからAIに渡す」](https://plain-text.net/wp-content/uploads/2026/03/image-16-1024x376.png)
もうひとつの問題として、「遊んだゲームがまたおすすめに出てくる」ことがありました。
これは普通に困るので、遊んだゲームはおすすめから除外し、さらに一度表示されたゲームは24時間再表示しないようにして、「次へ」を押すたびに新鮮なゲームが出てくるようにしました。
正直に言うと、レコメンドロジックは今も改善したいと思っています。
メタスコアを利用していることによる「品質と新鮮さ」のジレンマもありますし、表示されるまでの速度、推薦の精度などまだまだ満足できるものではありません。
これからは「使いながら育てていく」フェーズとしてレコメンドの改善を重ねていこうと思います。
この時期の教訓
2週間の開発で実感したことを整理すると、こうなります。
バイブコーディングの特徴として、画面(UI)はAIが出してくれるコードでどんどん先に進められます。でも「どんなデータが実際に取れるのか」を先に確認しないと、フィルタは空振りし、画面はスカスカになる。
完璧じゃなくていいので、最初に「このアプリが使うデータは何で、どこから取るか」だけは頭に入れておく。
それだけで後の苦労がだいぶ違います。
やってみたいと思ったら
セキュリティを知っておく用
バイブコーディングで認証を実装すると、「本当にこれで大丈夫?」という不安が必ず生まれます。全部読む必要はないですが、手元に置いておくと安心できる1冊です。
次回:後編
後編では、ランダムだったレコメンドをどう改善したか、デザインを作り直した話、名前をつけて公開するまでの話を書きます。
コメント